An intuitive introduction to Transformers
Attention Please!!
Introduction
“Attention is all you need”, the paper published in 2017, introduced the idea of transformers. Since then transformers have revolutionized natural language processing in several ways. They have become the backbones of many state-of-the-art models including the popular models like the BERT, GPT-3 (ChatGPT), and Dall-E.
Transformers are used in sequence-to-sequence translations. Sequence is an ordered set of tokens, in the context of NLP, a sequence could be an ordered set of words to form a sentence.
Transformers use an encoder-decoder architecture. The encoder extracts features from an input sequence, and the decoder uses the features to produce an output sequence.
Until recently various derivatives of the recurrent neural network (RNN) were used to perform the sequence-to-sequence translations. Though they provided good results, there were some drawbacks to using the RNNs.
Major drawbacks of RNN:
- RNNs have a short reference window. They do not work efficiently for longer sentences due to the vanishing or exploding gradients issue
- They consume more training time and must be run sequentially, leading to inefficient usage of the GPUs.
Transformers overcome these shortcomings. Theoretically, they have an infinite reference window, can run in parallel, and take less time to train.
In this article, we will try to get an intuitive understanding of the transformer architecture by taking an example of sequence-to-sequence word transformation.
Transformer —Model Architecture
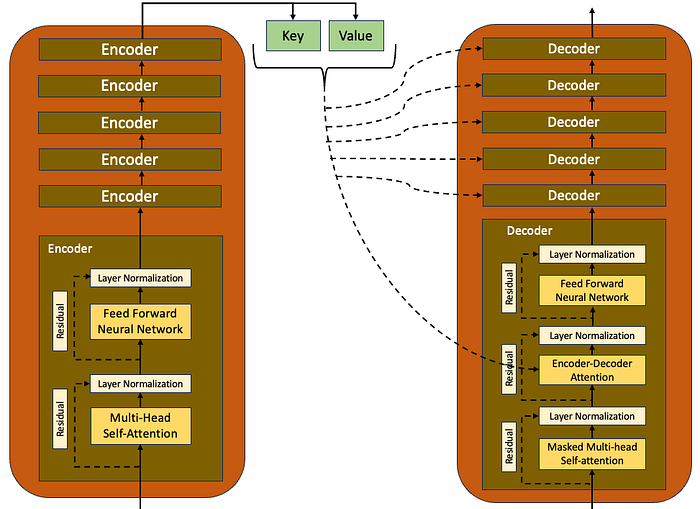
The model architecture as presented in the paper is shown below. The breakdown of this architecture into smaller blocks and the intuition behind each of the blocks is explained in the next sections.
Tip: If this looks complex now, refer back to this architecture after going through the article till the end :).
Transformer — Block Diagram

The above figure shows the major building blocks of the transformer. It is primarily made up of the following components:
- Input words preprocessors — word embedding & positional encoding
- Encoders
- Decoded words preprocessors — word embedding & positional encoding
- Decoders
- Output generators — linear layer and softmax layer
The details of each block are explained in the subsequent sections.
1. Input Word Embedding
- Machine learning algorithms cannot work on text data and needs to be converted to numeric
- In word embedding, each input word is converted to a numeric vector (dimension: 1x512)
- Related words will be close to each other in the vector space (or embedded space), e.g. the words “pen” and “paper” will be closer to each other as compared to the words “pen” and “pet”

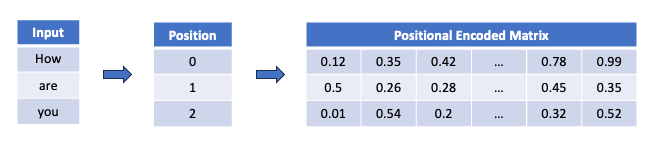
2. Positional Encoding (Encoder)
- Knowing the position of the word is important to understand the meaning of the sentence.
- Example: Notice the difference that the position of the word “only” can make in the following sentences:
Only I can answer your question
I can only answer your question - Unlike the RNN (where the time-step holds the position information), the word-embedded input has no information on the word position
- The positional information of each word is encoded using the sine and cosine functions, due to their linear properties
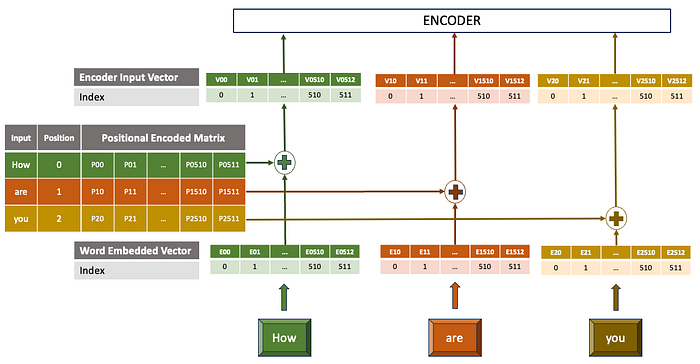
- The embedded vector and the positional encoded vector are summed up and passed as input to the first encoder layer
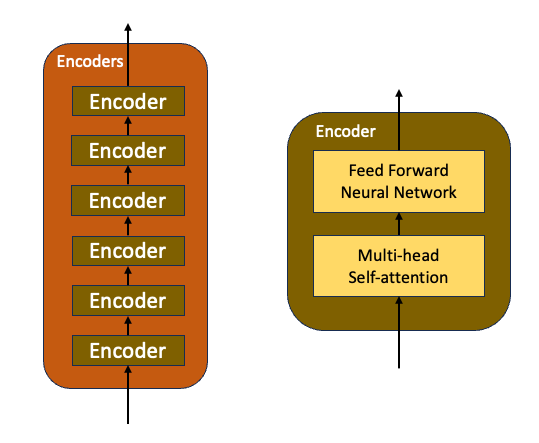
3. Encoders
- The encoders block explained in the paper consists of a stack of 6 identical encoder layers
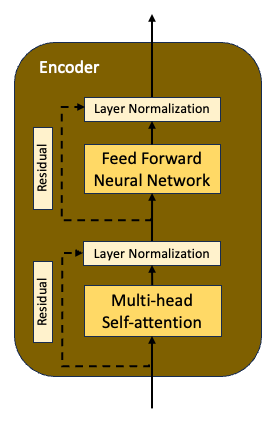
- Each encoder layer has two sublayers — a multi-headed self-attention layer and a fully connected feed-forward neural network
- Each sub-layer has a residual connection around it followed by a layer normalization
- All sub-layers produce an output of dimension 512
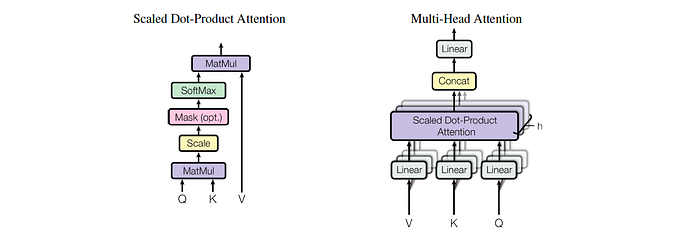
Encoder — Multi-headed Self-attention
Understanding the intuition behind Self-Attention
Why Self-Attention?
Let us start with the following example,
Tina was taking her dog for a walk. It was barking.
Does the word ‘it’ refer to Tina or the dog? Though it is obvious for a human to interpret that ‘it’ refers to the dog and not Tina, it is not the same for the machine.
Another example,
Tom was sitting by the river bank and looking at his bank statement.
The word ‘bank’ has a completely different meaning in each of its occurrences. Based on the context, it is easy for humans to associate the word with the right meaning but not for a machine.
Self-attention allows the model to associate the word with the correct meaning. It achieves this by determining how each word is related to other words in the same sequence. The idea is to capture the contextual relationship between the words in the sentence.
Query — Key — Value in Self-Attention
An analogy to the query-key-value concept is a library. Imagine you are searching for a particular type of book (query). There are books arranged on a shelf with only the titles visible. The titles become the keys. Based on the title (key) and your query, you decide how much attention needs to be given to each book. The value will be the amount of information extracted from the book to answer your query.
Another analogy, consider a database consisting of key-value pairs. When you have ‘query’, the system will check the query against the keys to find similar keys. If the key is similar, then it returns the specific value.
A similar concept is applied here. In the transformer, we are trying to find how each word is related to all the other words in the sequence. The word that is being currently processed becomes the ‘query’. The other words in the sequence form the keys. Based on the similarity of the current word with the other word, it decides how much attention has to be given to the other word. The information extracted using this attention score is the value.
Self-Attention — Diving Deeper
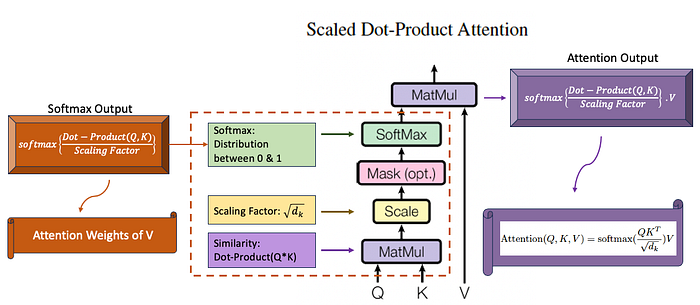
- The transformer model uses a scaled dot-product function, to all the words in the sequence, including itself to calculate the attention.
- What does “Scaled Dot-product Attention” mean?
Scaled → normalization
Dot-product → similarity index
Attention → weighted sum on attention weights - Dot-Product provides the similarity between words, hence the dot-product between the query and key is done here to know the similarity of the current word with each of the other words
- This layer has three learnable weight matrices, one each for Query, Key, and Value. These weights are trained during the backward propagation.
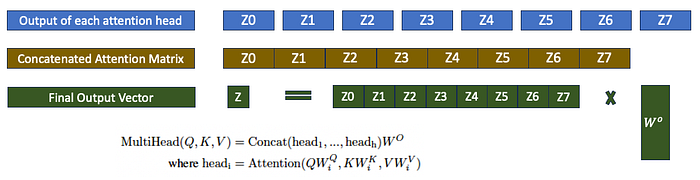
Multi-head Attention
- Multi-head attention can be considered as multiple copies of the self-attention mechanism applied in parallel.
- This further expands the ability of self-attention to focus on different positions of the sentence
- It uses multiple heads, i.e. multiple sets of weights for query, key, and value.
- For example, one attention vector could be focussing on the gender and another on the nouns/verbs in the sentence
- The attention layer uses 8 different attention vectors that are run several times in parallel.
- The output from each attention head is concatenated and linearly transformed (weight matrix, Wo) to form the output of the multi-head attention block
Encoder — Feed Forward Neural Network
- Each encoder layer has a fully connected feed-forward network (FFN) that is applied to every attention vector
- FFN is applied to each position separately and identically
- FFN is different for each sublayer, the input and output encoder layers have a dimension of 512 while the inner encoder layers have a dimension of 2048
Encoder — Residuals and Layer Normalization
- The residual connection is used around each of the two sub-layers, the attention layer and the feed-forward network, followed by layer normalization
- Normalization and residual connections techniques help the neural network train faster and more accurately
- The residual connection helps in mitigating the vanishing gradients problem in neural networks
- The layer normalization is used to stabilize the network and reduces the training time
Encoder Output
- The output of the final encoder layer, i.e. the attention vectors K and V are passed as input to each layer of the decoder
- This helps the decoder to focus on appropriate places in the input sequence
4. Decoded Word Embedding
- Each decoded output word is used as an input to the decoder in the next time step
- The word is converted to a vector format using embeddings, similar to the input word embedding
5. Positional Encoding (Decoder)
- Similar to the input position encoding, the position information of the decoded word sequence is directly put into the embedding of the sequences
6. Decoders
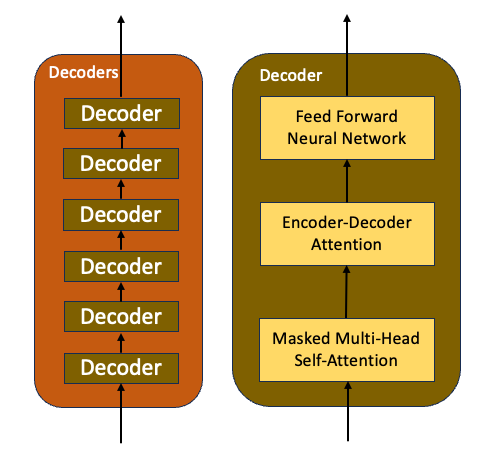
- Decoders are a stack of 6 identical decoder layers
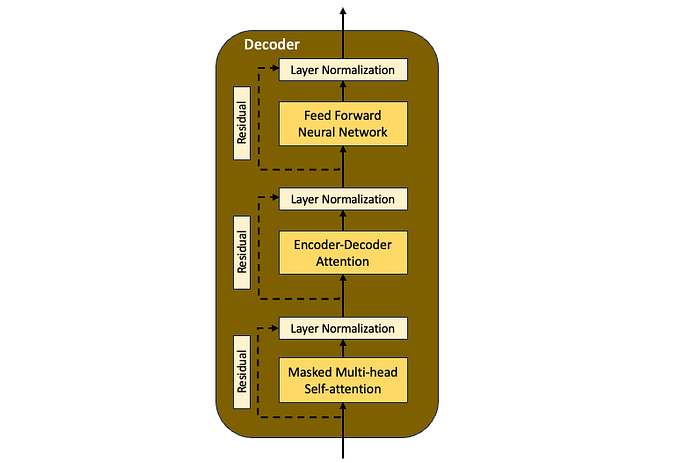
- In contrast to the encoder which has two sublayers, the decoder has three sublayers. A masked multi-headed self-attention layer, an encoder-decoder self-attention layer, and a fully connected feed-forward neural network
- Similar to the encoder layer, each decoder sub-layer has a residual connection around it followed by a layer normalization
- The transformer decoder uses the hidden states as a starting point and generates the output sequence one token at a time using the previously generated output as context
- The decoders are auto-regressive since it uses the previously generated output at each time step.
- The decoding process is run until the end of sentence token is generated as output
Decoder Layer— Masked Multi-Head Self-Attention
- Unlike the multi-head self-attention layer of the encoder that works on the complete input sequence, this layer in the decoder works with only the earlier (known) positions of the output sequence. Hence it is named as masked attention layer
- For example, for the output “I am fine” when the decoder is processing the word “am”, it should not have access to the word “fine” which will be generated in the future. The word “am” should only have access to itself and the words before it
- The future positions are hidden by masking them, i.e. by setting them to
-inf, before the softmax step in the self-attention calculation
Decoder Layer— Encoder-Decoder Attention
- The output from the last encoder layer, i.e. the attention vectors K and V are passed as input to the encoder-decoder attention sub-layer in each of the decoder layers
- The “Encoder-Decoder Attention” layer is similar to the multi-head self-attention layer except that it uses the Key and Query vectors from the output of the encoder and the Value vector from the output of the self-attention layer below it.
- This layer helps the decoder to attend to all positions and determine how each word in the input sequence is related to each word in the target sequence.
Decoder Layer— Feed Forward Neural Network
- Similar to the encoder, each decoder layer has a fully connected feed-forward network that is applied to every attention vector from the encoder-decoder attention sub-layer
- This layer normalizes the outputs and also aids in learning during backpropagation via residual connections
Decoder— Residuals and Layer Normalization
- The residual connections and the layer normalization help improve the flow of gradients and the overall performance of the decoder.
7. Output — Linear Layer
- The linear layer facilitates converting the vector of floats that is output from the decoder into a meaningful output
- It is a fully connected neural network that projects the output vector from the decoder into a larger logits vector
- Logits vector will have the size of the vocabulary it has learned from the training data. For example, if the training data has 1000 unique English words, then the output logits vector will be of size 1000, each cell representing the score of a unique word.
8. Output — Softmax Layer
- The softmax layer converts the scores in the logits vector into probabilities
- The most likely word will have the highest probability and the word associated with that probability is picked as output for the current time step
- The decoding process is executed multiple times until the end of the sentence token is generated for the sequence.
Loss Function & Feedback Loop
- The output of the softmax layer is a probability distribution, with each cell representing the probability of the output being that word. This is the output sequence.
- The target sequence in the training data is the expected probability distribution where only the expected word has a probability score of 1.0 and the rest of the words in the vocabulary have a score of 0.0
- The difference between the output sequence and the target sequence is the loss function which is used to train the transformer during the backpropagation
Summary
Here is a short summary of a Transformer
- The word embedding layer encodes the meaning of the word
- The positional encoding layer represents the position of the word
- Each encoder layer consists of a self-attention layer and a fully connected layer
- Each decoder layer consists of two self-attention layers and a fully connected layer
- There are 3 ways that the transformer uses the multi-head self-attention blocks, one in each encoder layer, and two in each decoder layer
- The linear layer and softmax layer convert the vector output from the decoder into meaningful output words
Hopefully, with this article, you would have got the basic intuition behind the Transformer architecture. Encourage you to read the paper “Attention is all you need” to get a deeper understanding.
Happy Learning!!
